Statistics for high-dimensional complex data with applications in lipidomics
M. Pesonen, J. Nevalainen
The proper use of statistics in lipidomics appears to be a new topic in biostatistical research. Such “omics” data sets (proteomics, genomics, lipidomics) are increasingly collected in biomedical research because of their apparent potential, but a shared view on a coherent analysis of such data sets has not been established. The present range of proposed methods for high-dimensional problems is large, including, for example, regularized regression, projection techniques and clustering methods, but none of them are especially tailored for lipidomics data. A systematic comparison of their use in lipidomics appears to be missing as well.
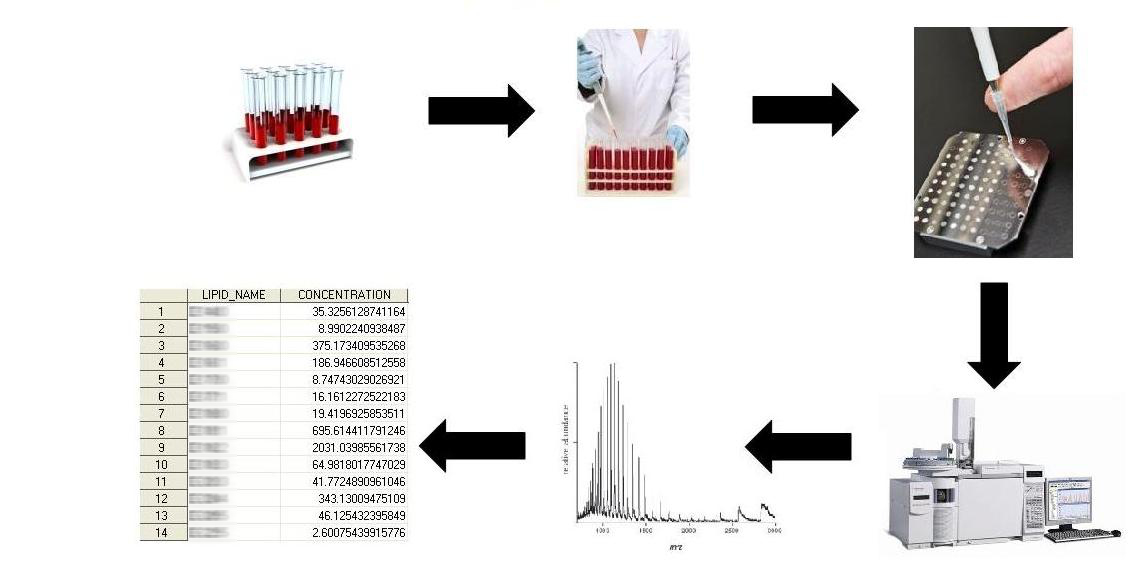
The goal of the project is to develop novel statistical methodology for complex high-dimensional data. Complexities arise from incomplete observations, within- and between-individual dependencies, and number of attributes measured. The developed methods will be applied in lipidomics data sets to help the research groups to make the most out of their data, to increase the knowledge and the understanding, and potentially, to have a public health impact. As a side-product, the project will enhance collaboration, in terms of exchange of information, practices and know-how, between academic and industrial communities.